当教育公司好未来想要训练自己的大模型时,它遇到了算力的难题。其算法工程师往往有多个项目、多个训练的模型、以及各种版本的迭代,任务繁多。在这个背景下,它们希望通过一个专业且稳定的算力训练平台,为每一个算法工程师分配合适的算力资源,让整个训练体系高效运转起来、将手上的算力利用到最优。
在大模型落地之路上,很多企业都面临像好未来一样的难题。当它们想要自己去训模型的时候,可能会遇到算力难以利用好的问题;当他们想要调用、调优模型时,可能会面临模型选择不够、工具链不够、数据不够等问题。
这正是国内云厂商想要帮他们解决的问题。在大模型浪潮下,过去以 IaaS(基础设施即服务)和 PaaS(平台即服务)为主的基础云服务,正让位于以 AI 为主的 MaaS(模型即服务)的云服务。云厂商希望能解决企业模型落地的这波需求,不仅仅是为了收模型和工具调度费,底层还是希望拉动云收入。
在大模型时代,围绕企业的不同落地需求,百度智能云推出了全栈的产品服务体系。
第一层是百舸计算平台,它基于百度对文心大模型训练的经验沉淀,主要为那些想自训模型的客户提供算力服务。好未来最终就选择了基于百舸训练自己的大模型。第二层是模型平台千帆,主要面向想直接调用模型、深入部署模型、以及基于模型进行上层应用开发的客户。早在去年 3 月,百度 C 端应用「文心一言」推出当月,百度智能云就及时推出了千帆平台。
这种积极性让百度智能云在 AI 大模型落地的进程中走在前列。据 IDC 发布的《2023 中国大模型平台市场份额》,中国大模型平台及相关应用市场规模达 17.65 亿元,百度智能云处于第一。而据自媒体”智能超参数”介绍,在 2024 年 1-8 月份的大模型中标数量盘点中,百度在中标项目数、行业覆盖数以及央国企中标项目数上,排名第一。
在 9 月 25 日百度智能云举办的云智大会上,百度集团执行副总裁、百度智能云事业群总裁沈抖介绍,目前大模型已经在企业端被真正用起来了。目前在千帆大模型平台上,文心大模型日均调用量超过 7 亿次,用户累计精调了 3 万个大模型,开发出了 70 多万个企业级应用。
在这样的背景下,百度智能云分别针对算力、模型、AI 应用,升级了百舸 AI 异构计算平台 4.0、千帆大模型平台 3.0 两大 AI 基础设施,并升级代码助手、智能客服、数字人三大 AI 原生应用产品。沈抖表示,大模型以及配套的算力管理平台、模型和应用开发平台,正在迅速成为新一基础设施。这是大模型走向千行百业的重要基础。
以下是极客公园与百度智能云、以及百舸和千帆两大产品体系负责人交流后,看到的这两款重要产品的核心变化。从中,可以一窥中国企业落地大模型的核心难点、关键趋势。这对于接下来国内大模型的落地进程或许是至关重要的。

百度集团执行副总裁、百度智能云事业群总裁沈抖|图片来源:百度智能云
对想训模型的客户:从「多快好省」用上算力,走向万卡集群时代
尽管直接调用模型是主流,但仍然有很多企业有自己训练模型的需求。据极客公园了解,这类企业往往集中在大模型初创企业、传统互联网企业,以及生命科学、智驾等行业。就企业规模来看,以行业头部客户居多。
它们一般具备较强的技术研发和快速迭代能力,有一定数据积累、数据质量良好。当然,它们也需要采购 GPU 算力。
但对于这些企业来说,如何能把算力用好,是一个核心难题。百度杰出系统架构师,百度智能云 AI 计算部负责人王雁鹏对极客公园表示,这些客户在算力上的核心痛点,大概可以总结为「多快稳省」。
1)多:指的是在算力卡脖子的情况下,企业必然要混合多种芯片训练,但芯片混训难度非常大。
2)快:指的是减少集群部署时间,提升模型训练推理效率,实现大模型业务快速落地。
3)稳:指的是技术故障都有可能导致训练任务停摆,进而造成损失,需要保持稳定和有效训练时长。
4)省:指的是算力没有被利用出来,甚至 50% 的算力都被浪费了,因此提升资源利用率对企业节省成本至关重要。
在王雁鹏看来,很多互联网行业客户的技术能力主要强于上层软件,而对于高性能计算、存储、网络、算法框架等底层基础设施能力上存在欠缺。他们想自己用好算力的难度比较大,这正是百舸平台提供的价值。
百舸延承自百度这十余年的基础设施经验,从最开始自己搭建服务器、到深度学习崛起后开始尝试 GPU 加速、到后来跟上云计算的巨大底层变革、再到今天 GPU 云时代超大规模的并行计算和万卡集群的算力利用。百度将过去多年的技术积累、资金与人员的大力投入、以及文心大模型的训练经验,最终沉淀为了百舸计算平台。


百舸 AI 异构计算平台 4.0|来源:百度智能云
在上述四大方面,百舸平台取得了领先于行业的产品优势:
1)多:百舸支持在同一智算集群中混合使用不同厂商芯片,兼容昆仑芯、昇腾、海光 DCU、英伟达、英特尔等国内外主流 AI 芯片,多芯混合训练任务的性能损失控制在万卡性能损失 5%,是业界最高水平。
|
王雁鹏介绍,实现多芯混训的核心,包括要在一套框架下面能把所有的芯片都用起来、因此要在抽象层把各个芯片打平;要建立芯片统一的通信库;要通过异构并行切分策略,解决不同芯片之间的互联带宽差异等。 |
2)快:一方面,百舸 4.0 能帮客户省去大量复杂和琐碎的配置和调试工作,最快 1 小时便能创建万卡规模集群,这要比行业通常需要的数天甚至数周快得多;另一方面通过大模型训推任务加速套件 AIAK,能针对主流开源大模型在并行策略、显存、算力等层面进行深度优化,为万卡集群下的大模型训推加速。比如单个芯片整体训练效率提升了 30%,长文本推理任务可以做到「极速生成」与「秒回」、效率提升了一倍。
|
王雁鹏介绍,这背后一方面是单卡训练的提升,基于具体场景做算子的加速库。目前,百舸聚焦在大语言模型和自驾模型两大核心场景,同时在算子层面进行加速。 另一方面是并行训练的提升,包括坚持使用 RDMA 进行大规模集群组网、包括一边计算一边通信、也包括显存的优化等,最终形成了并行训练的提升。 |
3)稳:大模型训练是一个庞大的单一任务,一个点出错,整个集群就得停下、回滚到上一个记忆点。百舸在万卡任务上可实现有效训练时长占比 99.5%,稳定性极强。
|
这背后在于降低故障次数和减少恢复时间,百舸在故障检测、故障诊断及定位、Checkpoint(检查点)及时写入、可观测能力、故障诊断、快速恢复等多个环节都进行了优化。 |
4)省:如果说一般客户自己管理算力只能发挥不到一半的资源利用率,那百舸能将资源利用率提升至 90%。
|
一方面是训推一体技术。如果说传统的模型训练和推理通常是在不同的集群中进行,导致训练阶段需要大量的计算资源和数据,而推理阶段对算力的要求则显著更低,造成资源浪费。那么训推一体技术是在不同时间使用 GPU 资源,让集群能同时支持在线推理服务部署、以及离线训练任务,从而提升资源利用率。 另一方面是弹性资源池技术。百舸是以弹性队列为核心去设计每一个任务的配额和各种分配策略,根据训练任务设计优先级、抢占策略、分配策略,进一步提升资源利用率。 |
正是看重百舸在稳定、高效提供算力等方面的优势,经过综合评估之后,好未来最终选择了百舸。好未来看来,百舸平台的自适应分配策略,无论是对并行模型、并行训练任务的处理,还是对单任务之间的快速衔接等,都能做到速度非常快、同时保证任务不掉,使得团队快速地完成了九章大模型的研发上线。
这些都还是在万卡集群的维度进行讨论,不过往未来看,国内大模型行业很快将进入十万卡集群的竞争。
沈抖介绍,大模型领域的 Scaling Law(缩放定律,指模型性能会随着参数、算力、数据集的规模增加而提高)仍在继续,这意味着大模型训练会很快进入十万卡集群的竞争阶段。不久前,马斯克表示刚建设了 10 万卡的集群,未来几个月还会扩张到 20 万卡,这不会是个例,
在他看来十万卡集群训练的挑战很大。一方面是空间,部署 10 万卡的大规模集群,光是在物理层面就要占据大概 10 万平方米的空间,相当于 14 个标准足球场的面积。另一方面是能耗,这些服务器一天就要消耗大约 300 万千瓦时的电力,相当于北京市东城区一天的居民用电量。
而这种对空间和能源的巨大需求,已远远超过了传统机房部署方式所能承载的范畴。因此不得不考虑跨地域的机房部署,但这又带来了网络层面的巨大挑战。另外 10 万卡集群的训练中断比例会大大提升,有效训练时长占比会非常低,这也是很大的挑战。
不过在沈抖看来,百舸 4.0 正是为部署 10 万卡大规模集群而设计的,而今天的百舸 4.0 已经具备了成熟的 10 万卡集群部署和管理能力。「它就是要突破这些新挑战,为整个产业提供持续领先的算力平台,让我们的客户始终走在时代前沿。」他说。
复盘大模型落地这一年:从试水、到中间阶段、再到真正的爆发
对于那些想要基于现有大模型做二次开发(包括再训练、微调、评估和部署)的企业来说,百度智能云千帆平台的初衷就是为它们打造。去年 3 月,千帆平台提供了大模型调用接口和微调工具链,帮助企业更好地进行大模型落地尝试。
而在百度副总裁谢广军看来,这一年半来,大模型落地趋势经历了三次变化。而针对这三次变化,千帆平台也相应完成了从 1.0 到 3.0 的三次版本进化。
千帆 1.0 推出时,正值大模型爆火,那是企业进行大模型落地的第一个阶段:接触大模型的人都在找卡、囤积算力、尝试训练模型,大模型带火了芯片和算力。那时大模型的需求相对模糊,千帆 1.0 主要提供给企业大模型调用和微调服务。
从去年下半年开始,大模型落地进入了第二个阶段:很多企业和开发者,都在探索怎么基于基座大模型改造现有业务,在模型调用之上新增了应用开发的需求。在这样的背景下,千帆推出 2.0,为企业提供 AI 原生应用开发工具。不过,这个过程虽然有很多企业在尝试,但真正用到生产中的并不多。
而从今年 5 月开始,受各家模型厂商的价格战影响、模型降价,加速了企业把大模型用起来,并在业务场景里产生价值。
自今年上半年以来,大模型的落地发展明显加快|图片来源:百度智能云
据百度智能云观察,自今年上半年以来,大模型的落地发展明显加快。就千帆平台的观察来看,其文心大模型日调用量超 7 亿次,累计精调模型超 3 万个,帮助用户开发 AI 应用应用超过 70 万个。
据谢广军介绍,大模型的应用已经进入爆发期,很多企业不是在等待类似移动时代的爆款应用,而是已经把大模型用到了自己业务的「研产供销服」的各个环节。
在他看来,这也是过去 18 个月整个国内大模型产业发展的一个缩影。「我们可以预判,2024 年将成为国内大模型产业应用爆发的元年。」他说。
企业的模型应用趋势:更深的模型工具链、更丰富的模型选择、更专业的应用开发工具
为了接住今天快速增长的 AI 落地需求,千帆大模型平台此次升级了 3.0 版本,在模型开发层、模型调用层、应用开发层三大方面都有了更新。如果拆解每一层,也能看到当下 AI 落地的一些需求和趋势。
1.模型开发层:需要大小模型结合、需要更深的工具链、需要补给数据
模型开发层,指的是需要基于现有大模型做二次开发(包括再训练、微调、评估和部署)。
据百度副总裁谢广军介绍,企业在进行模型开发时,一个需求是它们要的不只是大语言模型,也还需要传统的视觉模型、语音模型,甚至是传统意义上的小模型。比如在教育场景里,如果要大模型评判作业,它往往需要一个拍照的过程,通过 OCR 视觉模型解析题目,再通过大语言模型生成答案。
另外,企业进行模型开发的需求也更深度了。比如过去千帆提供的是低门槛一站式部署平台,但现在涌现了很多专业的用户,他们需要更深度的模型开发,比如白盒化训练、作业建模等方式开发等。
而在数据层面,企业也有了更高的要求。比如用户可能存在数据质量不高、数据不够、很难代表行业垂类场景的情况,那么就需要混入一些行业专有数据。另外,很多模型在训练时是针对具体场景做效果增强,但这可能会出现通用能力遗忘的问题,这时也需要混入通用的语料。
针对这些情况,千帆大模型平台 3.0 做了全面的更新。目前,它支持大模型和多种传统模型的协同开发,并提供了行业最全面的模型精调工具链,上线了 DPO、KTO 等模型训练算法和 PTQ 等模型量化算法。它还预置了独家高质量混合语料,支持企业将应用中产生的宝贵数据反馈给模型、形成数据飞轮,放大模型在特定场景下的优势。

千帆大模型平台 3.0 模型开发工具链|图片来源:百度智能云
一个案例是,高途教育通过千帆大模型平台的开发工具链训练了作业批改大模型。它可以准确识别印刷体的题干和手写体的学生答案,同时利用千帆「数据飞轮」对这些数据进行清洗和精标,进一步提升模型性能。现在,改大模型的数学判卷准确率已经能达到 95%,最终让老师、学生受益,让公司业务增长。
2.模型服务层:持续扩充模型类型、降低模型价格
模型服务层,指的是用户直接调用大模型的需求。
千帆平台的升级思路,一是持续扩充模型的类型。比如在主力模型上,推出了新的模型 ERNIE Speed pro、ERNIE Lite pro 等,上下文都是支持 128K。垂类场景模型上,又推出了包括 ERNIE Character、ERNIE Functions、ERNIE Novel,更好满足一些企业在细分场景的需求。
除了文心系列大模型外,千帆还提供了包括近百个国内外大模型等丰富模型选择。除了语言模型,还支持调用语音、视觉等各种传统的模型等等。
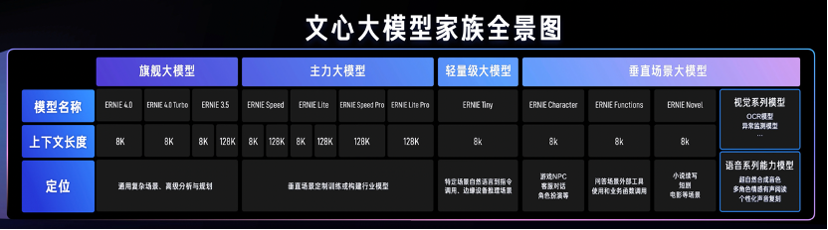
文心大模型家族全景图|来源:百度智能云
在扩大模型类型的同时,另一重点是降低模型调用成本。过去一年,文心旗舰大模型降价幅度超过 90%、主力模型全面免费。这带来的效果是,文心一言大模型的日均调用量超过 7 亿次。
上海巨闲网络科技旗下的产品「考试宝」,通过千帆的大模型调用和提示词工程,实现了试题解析智能化,可以秒级返回解析结果,用户会员转化意愿翻了一倍,且单条试题解析成本降幅达到 98%。最终实现了降本增收。
又比如是国内领先的招聘企业猎聘,通过调用文心大模型,对岗位需求和简历内容进行语义理解分析,帮助猎头顾问快速、智能地筛选简历,实现了高效的人岗匹配。现在,猎聘的人岗匹配准确率比业界平均水平高出 15 个百分点,提升招聘效率 50% 以上。
3.应用开发:企业级 RAG、企业级 Agent、AI 速搭三大方向
大模型真正在企业用起来,最上层的一步是看应用。它是一种最简单实用的方式,帮助企业用大模型来改造自己的业务。
目前,企业的的应用落地主要是在 RAG(检索增强生成)场景。因为 RAG 能让大模型快速「懂业务」,它相当于把海量的企业数据和行业知识做成「外挂知识库」给大模型。目前,千帆 3.0 从检索效果、检索性能、存储扩展、调配灵活性四方面对企业级 RAG(检索增强生成)进行了升级。
比如,通过与百度云资源打通,它可以支持无限容量的知识库存储和检索;速度上,能做到 1.5 秒内返回结果;RAG 全部关键环节,包括解析、切片、向量化、召回、排序等等,都可调、可配;企业可以灵活配置出最适合自己业务的方案;最后,它提供了企业级的安全性和稳定性。
在 2024 云智大会现场,演示了澎湃新闻应用企业级 RAG 的例子。这类权威媒体报道一条新闻时,往往需要引入该新闻的前因后果、背景信息,这是写报道的基础。澎湃新闻通过千帆创建知识库,上传了澎湃新闻成立十年以来所有媒资信息,共计 2700 万篇文档,超过 350 亿文字。接下来,设置成 100% 按知识库内容回答。
这对 RAG 的切片能力和召回的准确度要求非常高。比如让它盘点中国网球奥运发展史、以及 2024 年巴黎奥运女单冠军郑钦文的个人发展故事,大模型很快就定位到了知识库里的相关信息,并用结构化的表达方式生成了新闻事件的脉络、提供了文档索引。这体现了大模型强大的意图理解和内容生成能力。
又比如 RAG 的指令遵循能力。如果删掉知识库中有关郑钦文获得 2024 年奥运网球冠军相关的信息,再去问大模型,2024 年巴黎奥运会女单网球冠军是谁,大模型会拒绝回答这个问题。这是才是正确的做法。过去,由于大模型的「幻觉」问题,企业担心大模型不靠谱,但有了 RAG 和严谨的指令遵循,这个问题可以得到解决。
另外一个常见的大模型落地方式是 Agent(智能体)。Agent 在接到一个任务后,会进行自主思考、任务拆解、方案规划、并调用工具,全程自动地完成任务。千帆 3.0 升级的一个重要内容,就是针对企业级 Agent 的开发,增加了业务自主编排、人工编排、知识注入、记忆能力以及百度搜索等 80 多个官方组件支持。
在大会现场,也展示了在电商领域应用的例子。爱库存作为一家私域电商供货平台,数百万店主在爱库存上找到想卖的商品,通过自己的微信群、朋友圈这些渠道分发出去。爱库存正在千帆大模型平台上开发一个叫「爱库存超级助手」的 Agent。
过去,如果一个店主发现销量变差了,想调整一下销售计划、看看接下来适合卖什么。他首先要到数据看板上分析原因,如果确认是选品的问题,他会到爱库存「热卖榜」里去找更有增长潜力又适合他客群的品类,然后去做同类产品的比价、选品,最后还要到生成对应的文案和海报。这几步走下来,一般得几个小时。
而现在通过搭建 Agent,分钟级就可以完成,效率得到极大提升。目前这个功能正在内测,预计在 Q4 向爱库存的店主正式开放。
此外,本次大会还发布了企业级智能化低代码应用开发平台「AI 速搭」,通过自然语言对话,一句话就可以完成应用创建。
在大会现场,还演示了如何通过对话,在 AI 速搭平台上开发一个资产管理应用。只需一句话描述对目标系统的需求,包含资产信息、资产入库、资产领用、资产维修、资产报废等功能模块,大模型就可以清晰地理解需求并生成应用。过去,这样一个应用即使用低代码方式开发也需要几天的时间,现在只需几分钟就能完成。
大模型浪潮已经到了第二年,中国企业的落地速度、规模比想象中要更快。这离不开模型厂商以及提供全套落地产品体系的云厂商的努力。随着大模型落地真正拉开大幕,依靠响应速度、投入、决心等,百度智能云试图领跑、争夺 GPU 时代云计算巨头的生意规模和市场地位。今天或许只是一个开始。
文章来源:https://www.geekpark.net/news/341210













最新评论
苹果如果不支持微信,那它就是要退出中国市场了!
自己花钱买的座位,凭什么不能换?
不得不说蓝心妍很漂亮,我喜欢!
人间胸器
去了美颜滤镜,估计就是大妈了!
期待,不过感觉自己可能用不上了!
天涯不是彻底关闭了吗?
感觉长想一般般!