大模型发展到现在,我们应该关注什么?
像 OpenAI o1 这样的技术新范式是其一;像 canvas、NotebookLM 这样的产品新思路也是;还包括用户、客户营收这样的商业化指标。
目标多元,但资源有限。
进入 10 月,国内的大模型创业公司「六小虎」(月之暗面、Minimax、百川智能、智谱 AI、零一万物、阶跃星辰)开始在不同的道路上做出选择。
- Minimax 被传年营收预计 7000 万美金,同一时间流出的信息,还包括海螺 AI 由于视频大模型的推出访问量激增;
- 智谱清言 AI 搜索、月之暗面 Kimi 探索版,则相继推出了主打具备深度推理能力的 AI 搜索;
- 百川智能和阶跃星辰尚未释放进一步动作;
- 零一万物选择公布了最新模型进展,力破停止预训练等传言。
10 月 16 日,继千亿参数模型 Yi-Large 之后,零一万物正式对外发布新旗舰模型 Yi-Lightning,在国际权威盲测榜单 LMSYS 上,Yi-Lightning 超越 OpenAI GPT-4o-2024-05-13、Anthropic Claude 3.5 Sonnet,排名世界第六,中国第一。
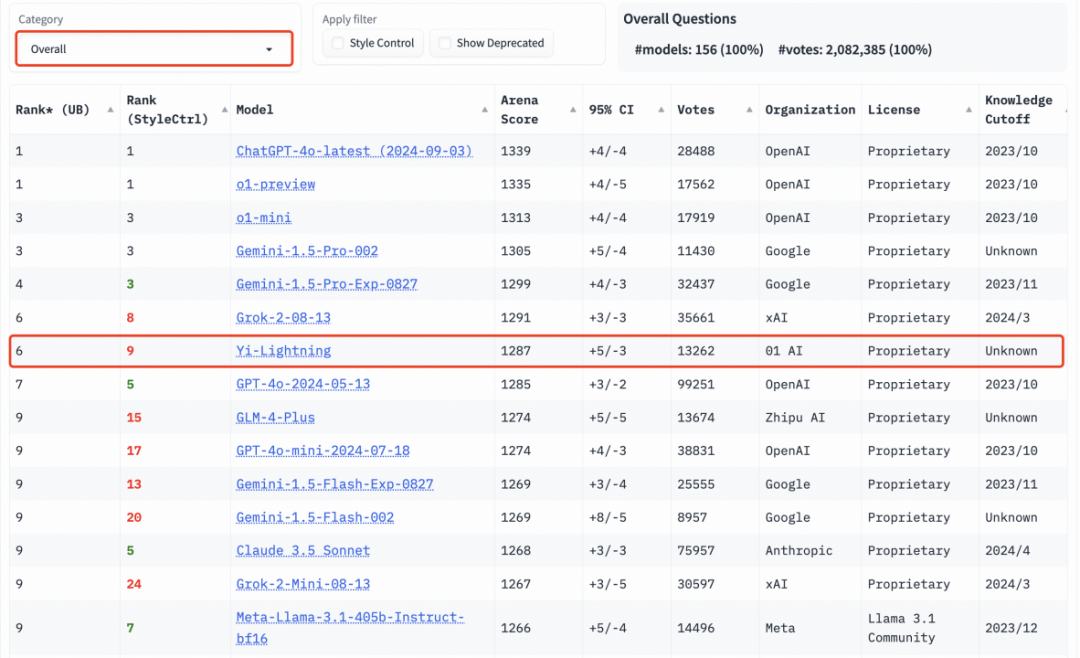
在国际权威盲测榜单 LMSYS 上,Yi-Lightning 超越 GPT-4o-2024-05-13、Claude 3.5 Sonnet,排名世界第六,中国第一。|图片来源:零一万物
对此,零一万物创始人李开复称 Yi-Lightning 是「顶级模型白菜价」,这是当前 AI 领域最需要的。他表示,「Yi-Lightning 和马斯克的 xAI Grok 打平,并列第六名;同时也是全球第三的中国大模型企业,排在零一万物之前的模型基本只有 OpenAI 和 Google」,这是中国大模型首度实现的最佳成绩。在推理速度和价格上,Yi-Lightning 的最高生成速度提速近四成,每百万 token 仅需 0.99 元,且该定价仍有利润。
李开复透露,这次预训练只用 2000 张 GPU 训练一个半月,只花了 300 多万美金,做出来的预训练模型跟 Grok 打平,只花它的 1% 或 2% 的成本。
进入 2024 年,鲜少有发布会只展示模型能力本身,AI 落地的产品、场景、客户案例等都成为外界关注的重点。会上,零一万物也首度公布了全新 ToB 战略下的首发行业应用产品 AI 2.0 数字人,聚焦零售和电商等场景。
对于 ToC 产品及海外进展,本次发布会上未作披露。今年 5 月 Yi-Large 的发布会上,零一万物预计今年营收预计可达 1 亿人民币。
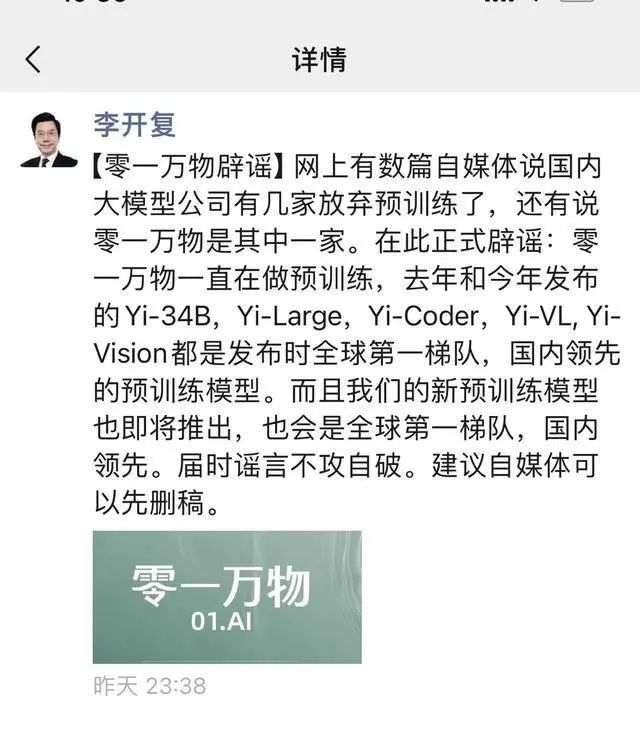
李开复在朋友圈辟谣|图片来源:网络
早在 5 天前,李开复已在朋友圈回应了停止预训练的传言,并在知乎上谈到了他对大模型接下来将如何洗牌的思考。今天 Yi-Lightning 的发布进一步回击了传言,李开复也进一步聊到了当前大模型竞赛中的几大争议。以下是他的思考,经极客公园整理:
01 六小虎分野之 01 万物的牌面:「顶级模型白菜价」
问:模型做到「世界第六,中国第一」,同时以较低的价格推向市场,如何实现的?
李开复:零一万物在 Yi-Lightning 的定价上并没有亏本。
成立第一天起,零一万物同时启动了模型训练、AI Infra、AI 应用三大团队,三个团队成熟后,再对接到一起。零一万物将这一模式总结为模基共建、模应一体两大战略。AI Infra 助力模型训练和推理,以更低的训练成本,训练出性能领先的模型,以更低的推理成本支撑应用层的探索。
我们不会赔钱卖模型,但也不会赚很多钱,而是在成本线上加一点点小小的利润,就得到了今天 0.99 元/百万 token 的价格。
挑选模型 API 最重要的一点,是模型性能一定要优秀,在这个前提之下才去挑最便宜的,我相信,综合 Yi-Lightning 的模型质量和价格来看,Yi-Lightning 很可能是很多开发者最认可、最高性价比的模型。
问:零一万物首次公布 ToB 相关矩阵,未来会进一步在 ToB 方向深耕吗?
李开复:在国内,大模型 ToB 相对于 AI 1.0 时代有不同的打法,首要任务就是要寻找少数能够按使用情况收费的方法,而不是项目定制的方法。能得到比较高利润率的订单再去做。
今天零一万物推出的 AI 2.0 数字人解决方案不是做一单赔一单的做法,它专注到用户重大的痛点需求和盈利点,也就是一个店长或 KOL 平时做一次直播浪费最重要的资源——他的时间。这个时间就算做一小时直播能赚到一千块钱,也就是这一千块钱,但如果用数字人直播就不是一小时了,可能可以做一千个小时(直播),哪怕每一个小时只能赚一半的钱,一千个小时还是可以赚五百倍的钱,这样账就很好算了。
如果真的能把数字人做到端到端,只要输入公司内部的东西,选一个形象、声音按一个钮就开始直播,等于卖给这个企业一个印钞机,印钞机要收租赁费就可行。除了直播以外,我们的 AI 2.0 数字人解决方案已经跑通了更多业务场景,比如 AI 伴侣、IP 形象、办公会议等等。
整体来看,零一万物 ToB 整体解决方案会采取「一横一纵」的打法。先将单个行业做深做透,进而以自身技术能力和行业积累为基础,凝练出标准化的 ToB 解决方案,为各行各业的企业客户将本提效。
问:除了数字人解决方案,零一万物是否还有其他 ToB 解决方案?
李开复:除了我们已经发布的 AI 2.0 数字人、API 之外,零一万物目前还有 AI Infra 解决方案、私有化定制模型等其他 ToB 业务,我们会在近期正式对外发布,敬请期待。
问:零一万物在海外推出 ToC 产品,国内陆续推出 ToB 产品,当前在 B 端、C 端的产品现状如何?
李开复:一个大模型公司同时做 ToB 和 ToC 很辛苦,销售方法、利润的比例、需要多少投放才会有收入等评估体系完全不同。也需要多元化的管理方式,因为两个团队的基因不一样,做事的方法、衡量 KPI 的方法都不太一样。我在这两个领域有经验,也在试着做,但也绝对不能什么都做。
ToB 上,零一选择做国内市场,是因为找到了一些破局的空间,比如用数字人来做零售、餐饮等,能做一个完整的解决方案。另外还有两三个领域开始在做,现在还不方便披露。ToB 不做海外市场,是因为全世界的范畴里,ToB 供应商基本都是当地的。选择在国内做 ToB,还要选择有利润的解决方案做,而不只是卖模型、不只是做项目制,这是我们 ToB 的做法。
ToC 我们主要布局海外。当我们开始做零一万物时,国内还没有合适的中文模型,只有在国外先尝试,迭代了一个、两个、三个产品,这些产品现在表现有些很好,有些没有那么好,在不断地调整中。
我们也在观察什么时候适合在国内市场做什么样的产品,目前做 ToC 产品面临一个很大的问题——流量成本越来越高。我们也看到有些友商的用户从十几块人民币加到三十多块人民币,近来还有相当的流失,在这样一个环境里,我们会非常谨慎,先不推出中国本土新的 ToC 应用,同时已有的产品还会继续维护,但更多的精力会在海外的土壤用更低的成本买到非常高质量的用户,或者能直接把 App 卖出去,让用户来订阅收费,那边订阅习惯相对成熟。
换句话说,现在现状选择在海外做 ToC 产品,变现能力和消耗用户增长的成本算账可以算得过来,以后再关注国内有什么机会可以推出。
02一轮预训练已降至 300 万美金,「六小虎」都可以 cover
问:此前有消息称 AI 方面的六小虎,某几家放弃了预训练。站在行业的角度,逐步放弃模型预训练会成为行业整体趋势吗?
李开复:做好预训练模型是一个技术活,而且要非常多有才华的人在一起工作,慢工出细活。需要有懂芯片的人、懂推理的人、懂基础架构的人、懂模型的人、很好的算法同学,一起做出来。
如果一个公司能有幸拥有这么多优秀的人才,能够跨领域的合作,我相信中国绝对可以做出世界排名前十的预训练的通用模型,但不是每家公司都可以做这件事情,做这件事情的成本也比较高,以后有可能会越来越少的大模型公司做预训练。
不过据我所知,这六家公司融资额度都是够的,我们做预训练的 production run,训练一次三四百万美金,这个钱头部公司都付得起。我觉得中国的六家大模型公司只要有够好的人才,想做预训练的决心,融资额跟芯片都不会是问题的。
03 AGI 的上限:o1 开启推理层面的新范式,OpenAI 还藏着技术
问:今年 5 月份,Yi-Large 把中美顶尖模型的时间差缩短到六个月,这次 Yi-Lightning 发布直接击败了 GPT-4o,把时间差甚至缩短到了五个月,零一万物如何能继续追赶缩短这个时间差?
李开复:缩短时间差非常困难,我不预测我们可以缩短这个时间差。因为毕竟人家是用十万张 GPU 训练出来,我们用的是两千张 GPU 训练出来。
Yi-Lightning 的效果是因为团队和社区大家都热心聪明去使用,去理解对方做出来的东西,再加上我们自己每家的研发有特色,比如数据处理、训推优化等等,现在这一套方法论在零一万物已经成熟了,我们有信心把自己的创新加上我们的一些特长,在关注 OpenAI 和其他公司发布的新技术,尽快地去能够了解这些技术的核心重要性,然后把它的能力在我们自己的产品里面发挥出来。
我觉得这套方法保持在六个月左右,就已经是很好的结果了。如果期待破局,可能需要一个前所未有的算法才有机会。我们千万不要认为落后六个月是一个很羞耻的事情,或者一定是要追赶的事情,因为我很多海外朋友都认为中国会远远落后,人家十万张 GPU 等,我们要被甩掉三年、五年甚至十年都有可能,现在零一万物证明了不会落后这么多,而且这次 LMSYS 的榜单上也有其他两家中国公司表现不错。
问:OpenAI 的 o1 发布后,从技术上带来在推理侧的 Scaling 新范式,你怎么看?对初创公司会有哪些影响?
李开复:OpenAI 真的是很厉害的公司,在他们的员工交流时,他们说OpenAI 内部还有一些好东西,但是不急拿出来,因为他们领先行业足够多。这次他们把 o1 拿出来主要是因为 GPT-5 训练不顺利,而他们需要融资,就先把 o1 公开,这是他们能做而别人不能做的。
OpenAI o1 虽然隐藏了所有中间的思考状态,但是很多人还是在网上开始猜它怎么做,我们认为有一些揣测还是比较靠谱,所以当你发了一个新技术,这个技术被很多聪明人使用、揣测,我觉得五个月以后,应该也有不少类似 o1 模型的能力出现在各个模型公司,包括零一万物。
o1 的思考模式是把之前只在预训练中 scaling 的趋势扩展到了推理,这件事情对行业是最大的认知的改变。过去大家觉得谁预训练做好就够了,慢慢大家发现后训练 SFT 和强化训练都是非常重要。
所以零一万物的团队刚开始做的主要是专注预训练,之后又有很多很厉害的人加入,帮我们把后训练也做出来,现在看来推理也很重要,感谢 OpenAI 点醒我们这一点,相信现在很多中美公司都在往 o1 方向狂奔。
*头图来源:视觉中国
本文为极客公园原创文章,转载请联系极客君微信 geekparkGO
文章来源:https://www.geekpark.net/news/342033












最新评论
苹果如果不支持微信,那它就是要退出中国市场了!
自己花钱买的座位,凭什么不能换?
不得不说蓝心妍很漂亮,我喜欢!
人间胸器
去了美颜滤镜,估计就是大妈了!
期待,不过感觉自己可能用不上了!
天涯不是彻底关闭了吗?
感觉长想一般般!