虽然大模型的评测榜单已经泛滥,但 LiveBench 却是实打实的大有来头。
LiveBench 是由图灵奖得主、Meta 首席 AI 科学家杨立昆(Yann LeCun)联合 Abacus.AI、纽约大学等机构推出的大模型测评基准。LiveBench 从包括数学、推理、编程、语言理解、指令遵循和数据分析在内的多个复杂维度对模型进行评估。之所以名字里有个「live」,就是因为这个榜单采用了新颖的数据来源并保持每月更新,这杜绝了大模型通过预训练和微调作弊的可能性。LiveBench 也被行业内誉为「世界上第一个不可玩弄的 LLM 基准测试」,官网上明晃晃地写着「A Challenging,Contamination-Free LLM Benchmark」。
简单来说,经常对着当今由 OpenAI 引领的大模型技术路线一通抨击的杨立昆牵头做了一个对刷榜行为异常警觉的大模型评测基准——而就是这样一个十分严苛的榜单,Step-2 在其中 IF Average(Instruction Following,指令遵从)一项中拿到了第一。
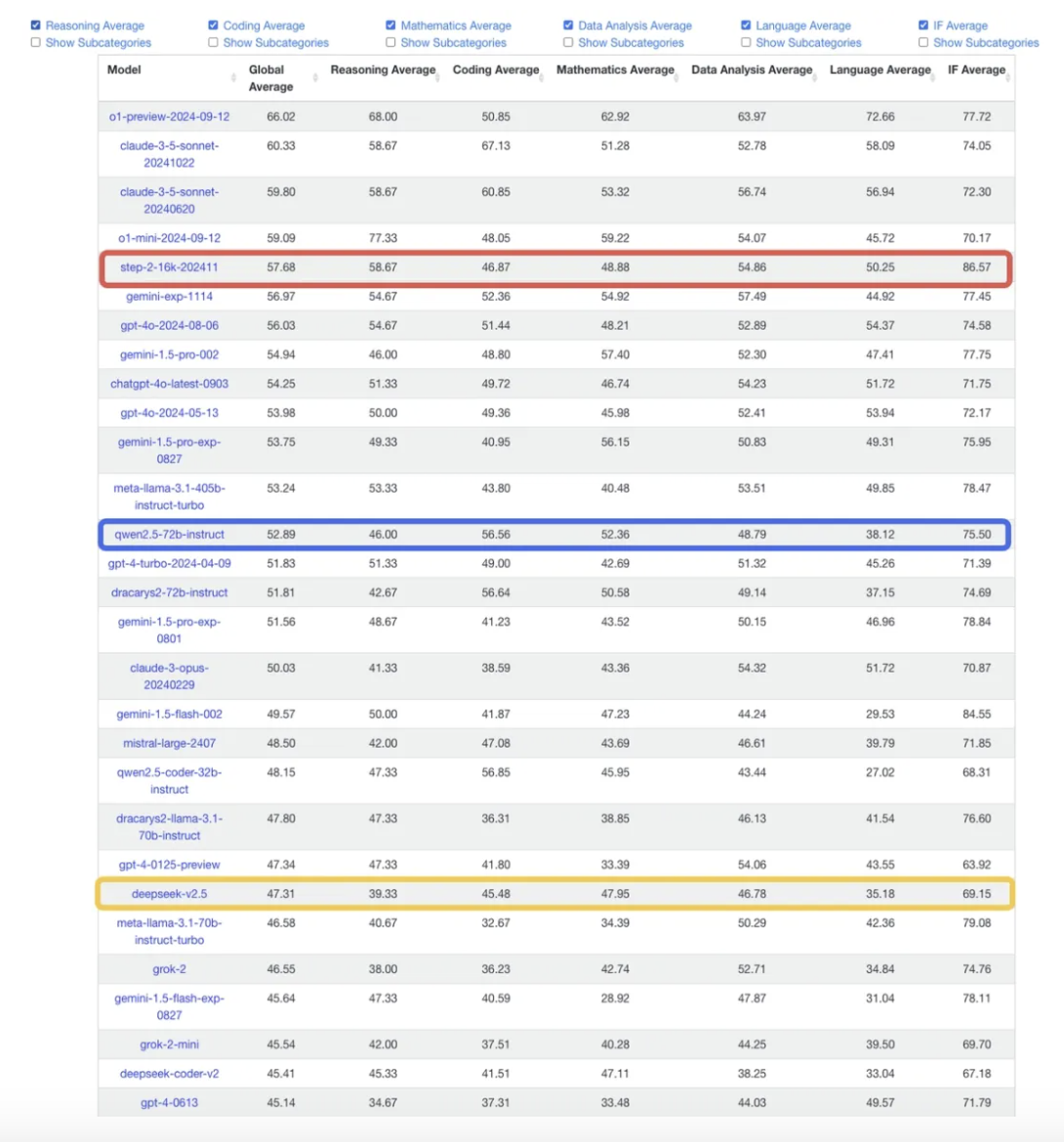
根据评测基准 LiveBench 的论文中叙述,测评团队在 IF Average 测试中为模型提供了一篇来自《卫报》的文章,要求模型遵循多个随机抽取的指令,同时要求模型完成与文章相关的四个任务之一:释义、简化、故事生成和总结。然后根据任务对指令的遵守情况来评分。评测结果是 Step-2 拿到了 86.57 的平均分,gemini-1.5-flash-002 得到了 84.55,在这两个唯二超过 80 分的模型之后,meta-llama-3.1-70b-instruct-turbo 以 79.08 紧随其后,而以推理能力见长的 o1-preview-2024-09-12 得到了 77.72 分。
从 LiveBench 的测试结果看,目前 Step-2 在指令遵从的能力上力压了当今所有国内外语言大模型。
01
强劲的 Step-2 万亿参数模型
说 Step-2「异军突起」或许并不准确。
阶跃星辰在今年 3 月发布了 Step-2 语言大模型预览版,是当时国内首个由创业公司发布的万亿参数大模型。此后的几个月内,阶跃星辰快速迭代 Step-2,在 2024 年 WAIC(世界人工智能大会)期间对外发布了这款模型的正式版,彼时 Step-2 在数理逻辑、编程、中文知识、英文知识、指令跟随等方面体感已经全面逼近 GPT-4。目前,阶跃星辰 C 端智能助手「跃问」已经接入了 Step-2 语言大模型,在跃问 App 和跃问网页端皆可体验。
但以成长速度来说,Step-2 用四个月追到与 GPT-4 几乎身位平行,又用了 4 个月完成对 Gemini-1.5 和 GPT-o1 部分能力的反超,步子迈的确实很快。
但这也并不让人太过意外,由于特殊的 MoE 架构,Step-2 从最初就被视为极富成长性的「高潜力」基础模型。
在大规模语言模型(LLM)的发展过程中,Mixture of Experts(MoE)架构因其独特的优势受到越来越多的关注。这种架构通过选择性地激活部分专家网络,在提升模型性能的同时保持了较高的计算效率。而目前训练 MoE 模型主要存在两种策略:一种是基于已有模型的 upcycle(向上复用)训练,另一种则是从头开始训练。
Upcycle 训练是一种利用现有模型进行训练的方法。它的优势在于对计算资源的需求较低,训练效率高。因为可以复用已有的模型参数,训练过程更快。这种方法适合在资源有限的情况下快速开发和验证模型。然而,upcycle 训练的缺点是模型的性能上限较低。由于基于已有模型的拷贝,专家网络可能会出现同质化问题,即多个专家学习到相似的特征,限制了模型的多样性和最终性能。
相比之下,完全从零构建和训练 MoE 模型,面临着更高的训练难度和更大的资源投入,但同时能够带来更高的模型性能上限。这种方法允许开发者设计更为复杂和多样化的专家网络,使得每个专家网络都能够学习到更加独特和专门化的特征。同时也提供了更大的灵活性,开发者可以根据具体需求对模型架构进行精细的调整和优化。
市面上所谓的 MoE 大部分是前者,而阶跃星辰团队在设计 Step-2 MoE 架构时候选择了后者。
这也意味着 Step-2 每次训练或推理所激活的参数量都超过了市面上的大部分 Dense 模型。也让 Step-2 有了另一个更让外界印象深刻的标签——万亿参数模型。而往往更大参数的语言模型意味着更好的交付效果,特别是在指令遵循、内容创作和语义理解层面。
02
跃迁式进化的阶跃星辰
阶跃星辰的名字来自于「阶跃函数」。
阶跃函数(Step Function)是一种分段常数函数,其特征是在某些特定点上发生突变,即函数值在这些点上会突然从一个常数值跳跃到另一个常数值。这种函数通常用于描述系统中某种瞬时的变化或状态的切换。
在神经网络中,阶跃函数可以用作激活函数,帮助模型在输入达到某个阈值时激活输出。这种激活过程可以视为一种超线性增长,因为输出在某个点上突然变得显著。
阶跃星辰也带着相似的某种跃迁和超线性的感觉,这家大模型初创公司没有喧闹的天性,每次回到公众的视线内都意味着有了重大的能力提升。
除了语言大模型 Step-2,阶跃星辰也很早就在 Step 系列通用大模型家族中展开了多模态方面的探索。在 2024 年 3 月,阶跃星辰推出了千亿参数的多模态大模型的第一个版本 Step-1V,在 7 月的 WAIC 期间,阶跃星辰一口气连发三款 Step 系列通用大模型新品。除了 Step-2 万亿参数语言大模型正式版之外,也包括 Step-1V 的迭代版本 Step-1.5V 多模态理解大模型,以及 Step-1X 图像生成大模型。
半年时间,阶跃星辰从万亿参数的语言大模型出发,迅速完成了语言模型和多模态模型的齐头并进。
在 Step-2 万亿参数大模型的加持下,Step-1.5V 多模态模型在图像感知和理解能力上全面提升,并具备出色的视频理解能力。它能准确地识别视频中的物体、人物和环境,并理解视频的整体氛围与人物情绪。除此之外,Step-1.5V 有着非常可观的推理能力,能根据图像内容进行解答数学题、编写代码、创作诗歌等高级推理任务。基于这款模型,阶跃星辰还在 C 端智能助手「跃问」上线了智能视觉搜索功能「拍照问」,用户可以即拍即问,比如拍美食图计算卡路里、拍场景学习英文单词等等。
如果说 Step-1.5V 的发布,标志了阶跃星辰在极短的时间内实现了从图像理解到视频理解的跨模态升级,那么新发布的 Step-1X 图像生成大模型,则代表了阶跃星辰在推动多模态理解和生成一致性的技术路线上也有了重要进展。
Step-1X 采用全链路自研的 DiT(Diffusion Models with transformer)模型架构,支持 600M、2B、8B 三种不同的参数量,能够满足不同场景的需求。并且 Step-1X 具备强大的语义对齐和指令跟随能力,还针对中国元素和文化进行了深度优化,更具中国风格。这也是 Step-1X 区别于其他模型的重要特色。
除了在基座模型层面布局全面、快速迭代之外,阶跃星辰在产品化上步伐同样迅速:智能助手「跃问」和 AI 开放世界平台「冒泡鸭」,是阶跃星辰面向 C 端用户推出的两款产品。
基于 Step 系列通用大模型的强大能力,「跃问」能准确地描述和理解图像中的文字、数据、图表等信息,不仅能出色地完成内容创作、逻辑推理、数据分析等任务,也能满足人们在生活场景中的各种需求,比如可以拍图介绍文物古迹背后的历史知识、帮忙制订旅游攻略、辅助健康管理等等。
「冒泡鸭」则打造了一个全新的 AI 开放世界。在这里,用户可以探索故事、创作角色,沉浸属于自己的开放世界。
目前 AI 应用普遍面临用户使用门槛偏高的问题,阶跃星辰也在通过一系列产品创新,让 AI 应用获得更多普世化场景,能够真正为每个人解决问题。近期,「跃问」将智能视觉搜索功能「拍照问」接入了 iPhone 16 新发布的相机控制按钮,支持用户一键调用智能问答搜索。是国内首个将大模型能力接入 iPhone 16 的大模型厂商,在多模态能力与硬件的结合上迈出了引人注目的一步。
在阶跃星辰 CEO 姜大昕看来,模型和应用的关系犹如「灵魂与皮囊」,两者的深度绑定才是实现技术极致的关键,应当形成一种协同进化的关系。应用将抽象的模型能力投射进现实,而模型能力最终决定着一切的上限。
近几个月,OpenAI 发布的 o1 一定程度上印证了大模型此前并未受到足够重视的技术方向,也就是强化学习以及强化学习所带来的在推理和规划能力上的突出表现。而在阶跃星辰最初「模拟世界、探索世界和归纳世界」的 AGI 发展路线图中,世界模型和强化学习就在确定要攻克的版图上。
现在大模型技术曲线从陡坡放缓的大背景下,无论是模型多模态的能力、杀手级 AI 产品的出现,或者对强化学习训练更好地运用,诸多亟待突破的地方,希望又比以往任何时候都更明确的落在基础模型的能力上。
Step-2 和整个 Step 系列模型,或许就是那个阶跃星辰撬动世界的支点。
文章来源:https://www.geekpark.net/news/343476












最新评论
苹果如果不支持微信,那它就是要退出中国市场了!
自己花钱买的座位,凭什么不能换?
不得不说蓝心妍很漂亮,我喜欢!
人间胸器
去了美颜滤镜,估计就是大妈了!
期待,不过感觉自己可能用不上了!
天涯不是彻底关闭了吗?
感觉长想一般般!