在通往 AGI 的路上,绝大多数公司的路线是不断做大参数,但面壁智能却走了一条相反的路线——尽可能把模型参数做小。
2 月 1 日,面壁智能推出了只有 2B(注:20 亿)参数量级的模型 MiniCPM,而其性能却超过了大参数模型 Mistral-7B(法国大模型公司 Mistral 旗下知名模型)、且部分超越 Llama-13B(Meta 旗下知名开源大模型)等,内部称之为「以小博大」。
这个结果揭露了这样一个事实:很多超大参数的大模型,它们的模型效率或许并没有最大化。
「我们希望探索模型性能的天花板。」面壁智能联合创始人刘知远教授称。他认为,从技术研判而言,2023 年 ChatGPT 和 GPT-4 的推出,表明大模型技术路线已经基本确定,接下来就是要探索其科学机理,并极致地优化效率。
他表示,在 Mistral-6B 的同一模型水平下,面壁智能团队的模型参数量是最小的。这或许意味着模型的效率被提升到了最高水平。「我觉得我们做了一件挺牛的事。」他笑着说。
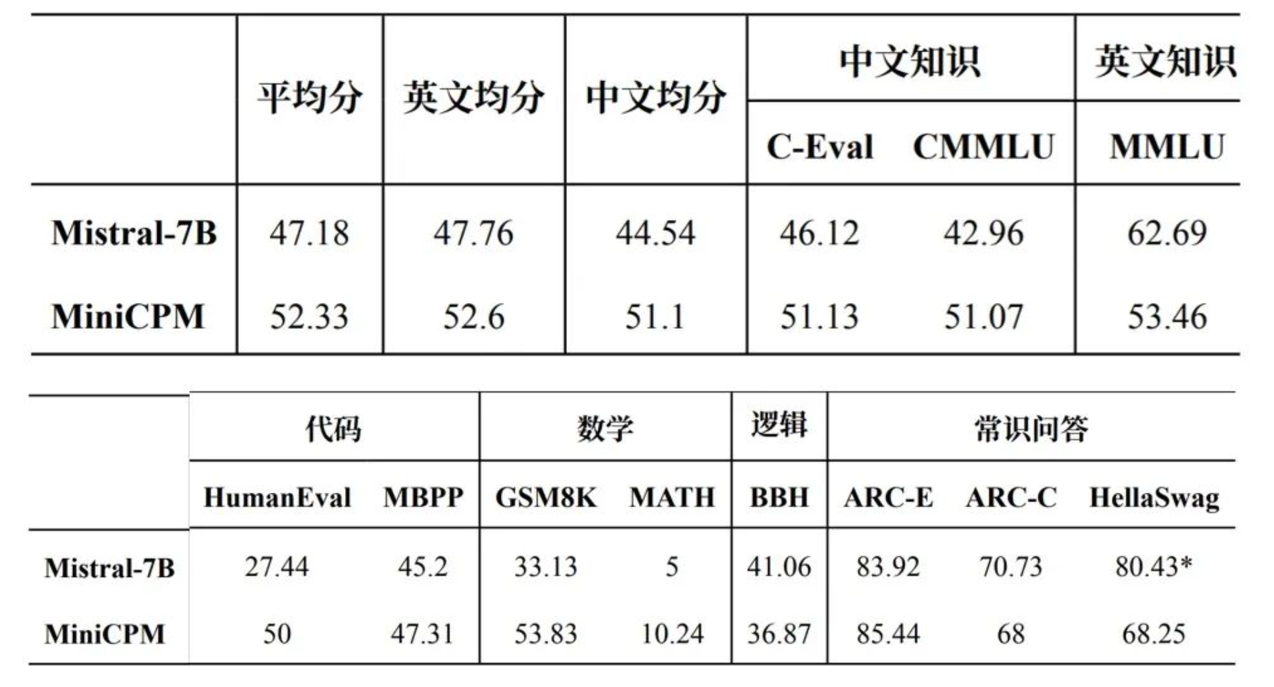
MiniCPM 在多项主流评测榜单、中英文平均成绩超越 Mistral-7B | 面壁智能
面壁智能成立于 2022 年,由清华 NLP 实验室的刘知远副教授带头成立。这是国内最早研发大模型的团队之一,早在 2020 年,团队就发布了全球首个 20 亿级中文开源大模型 CPM。直到去年 4 月,面壁智能接受了知乎投资,不久后知乎 CTO 李大海成为面壁智能 CEO。这家公司开始完成从学术界到商业界的转身。(见极客公园专访《对话面壁智能:和知乎的优势互补,会加速大模型的研发》)
此次面壁智能做小参数模型背后,不仅是为了挑战模型训练技术,更有深远的现实和商业意义。
更小的参数意味着更低的部署门槛、更低的使用成本——这意味着它能在手机等终端上运行,甚至仅靠一块 CPU 就能运载,面壁智能因此将 MiniCPM 称为端侧大模型——它带来的意义是,模型能被更广大人群应用、也有更好的商业化前景。
「无论是面壁还是清华 NLP 实验室,我们的梦想就是实现 AGI(通用人工智能)。任何完成这个目标需要做的,就是我们要做的事情。」关于 MiniCPM 背后的思考决策,刘知远如此说道。
模型训练不再「玄学」
面壁团队之所以尝试「以小博大」路线,跟 Mistral-7B 有些渊源。
去年 9 月,刚发布的 Mistral 7B 是「以小博大」的标杆之作:它只有 7B 大小,却击败了参数量大得多的 Llama(注:所有基准测试中均优于 Llama 2 13B、并在许多基准测试中均优于 Llama 1 34B)。这引起了整个大模型行业的广泛关注。刘知远说,自此之后他心里就种下种子,希望让团队也尝试一下模型「以小博大」。
这极其考验模型的训练技术和效率。
一直以来,大模型的训练过程被戏称为「炼丹」:核心是加大参数,整个训练过程却难以捉摸、全凭感觉,很少沉淀为科学系统的训练技术——不过,各大模型团队都在为此努力,希望将自家的训练技术从「玄学」变成「科学」。
面壁智能也在做这样的尝试。2023 年,团队做了上千次的「沙盒实验」(注:在拟真测试环境下,通过控制变量等方法,找到模型训练背后的科学原理和规律),对大模型的训练机理有了较为深刻的理解。「就像造飞机需要空气动力学的支持,我们团队致力于把大模型的研究科学化。」刘知远说。
这也是他想研发 MiniCPM 的重要原因,「我想检验一下我们(总结)的训练科学,是不是真的科学。」他说。

面壁智能模型「沙盒试验」| 面壁智能
结果验证了他的期待。仅通过两周的训练,MiniCPM 就成功实现了以小博大。这证明了团队的训练技术符合一定科学。刘知远称,此次结果是过往沙盒实验「厚积薄发」的结果。「我们希望通过 MiniCPM 让大家认识到,即使 2B 尺寸大模型的效果极限,还没有被充分挖掘出来,这是一个科学问题也是一个技术问题,需要大家共同探索。」他说。
目前,面壁智能团队已将 MiniCPM 背后的训练方法、过程写成文章,发布到 Github 上。
当然,除了训练技术本身,其他的要素也很重要——比如优质数据集、Infra(AI 基础设施层的软件) 等。此次,面壁智能仅靠 1TB 的精选数据训练就完成了模型的「以小博大」,当问到数据的来源是否跟知乎有一定关系时,「知乎起了很重要的作用,但最终还是算法自动选取的结果。」李大海对极客公园说。
Infra 方面,面壁智能表示,团队全流程优化加速工具套件平台,可以实现 10 倍推理加速,90% 成本降低。

面壁智能阐述如何让模型「以小博大」| 面壁智能
或许因为诸多因素才研发出了 MiniCPM,所以团队并不担心公开训练的方法、过程。「说实话就算我写出来了,别人也不一定能做出来。这或许就是我们的壁垒。」MiniCPM 的模型训练负责人、面壁智能研究员胡声鼎说。
端侧小模型,「直供」手机厂
作为一款小参数模型,MiniCPM 能部署在手机等终端设备上,主要被定位为端侧模型。目前,MiniCPM 已跑通了国际主流手机品牌和终端 CPU 芯片。
为什么有了云端模型,依然要端侧模型?从用户的角度来说,假设遇到极端的断网等情况(面壁团队现场举了户外探险的例子),用户依然可以通过端侧模型获得服务。这实际上拓宽了用户使用模型的场景。
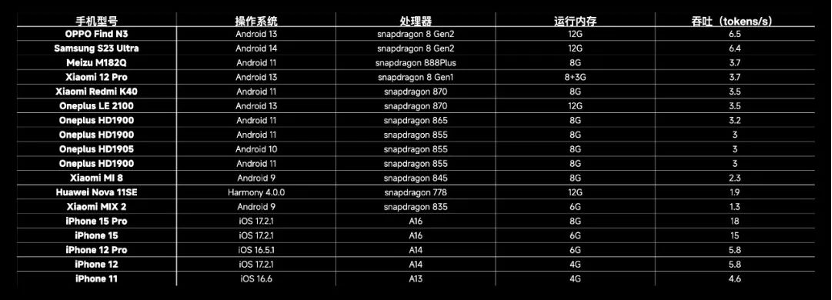
MiniCPM 可搭载的手机型号 | 面壁智能
而从开发者的角度来说,端侧模型能帮助他们减轻算力负担、降低算力成本。
以算力负担为例,李大海称假设大模型领域出现了超级应用,需要成百上千万人同时在线,用户都在云端使用模型的话,算力带宽和成本,对于创业团队来说都将难以承受。
以算力成本为例,李大海现场用一台搭配骁龙 855 芯片(高通于 2018 年推出的手机芯片)的手机做了一道数学题。按照运行 5 年计算,每秒 7.5 tokens,那么 170 万 tokens 的推理成本仅需人民币 1 元,成本仅为 Mistral-Medium 的百分之一。
刘知远认为,未来大模型一定是云端共存、协同的模式——就像人类的智能需要分布于大脑、小脑,未来的大模型的智能也会分布于云、端——它们各有不同的分工,就像大脑负责高级智能、小脑负责基础智能一样,未来大模型的高级智能将由云端实现,而基础智能将由终端实现。
自去年 7 月以来,大模型上终端一直是行业普遍趋势。荣耀、华为、小米、OPPO、vivo 等手机厂商均推出了自己的终端大模型。当问到相比手机厂商,面壁智能做终端大模型的优势是什么时,李大海称未来如果云端需要联动,由同一个模型厂商做会更高效。
目前,面壁正在跟许多终端厂商沟通,探讨将 MiniCPM 这款小模型落地的可能。

面壁智能 CEO 李大海、联合创始人兼首席科学家刘知远。图源 | 面壁智能
如果说云端模型主要卖的是 API 调度费、解决方案,那么端侧模型的商业模式或有所不同——李大海表示,目前 MiniCPM 已经开源、经授权后可商用,未来将主要从模型授权费中获取商业收入。「端侧模型有端侧模型的落地模式和场景,(云端)大模型有(云端)大模型的落地模式和场景。」他说。
和 Meta 一样,面壁也是将 MiniCPM 这样的端侧大模型和其它规模较小的大模型开源,将旗下 CPM-Cricket 等千亿大模型闭源。目前,面壁智能的模型收入主要来自 B 端,主要集中在金融、营销等领域,目前已有招商银行、易车网、义乌小商品集团等客户。
谈及面壁智能未来的发展规划,李大海称,一方面是继续加强模型能力,无论是小模型还是大模型,并在此基础之上继续探索 Agent、上层应用的发展。另一方面则是探索落地和商业化。
「说实话我对我们的模型技术能力有信心,所以未来我们的重心会放在商业化上。」他说。
附:
GitHub 项目地址
https://github.com/OpenBMB/MiniCPM
HuggingFace 项目地址
https://huggingface.co/openbmb/MiniCPM-2B-sft-bf16













最新评论
苹果如果不支持微信,那它就是要退出中国市场了!
自己花钱买的座位,凭什么不能换?
不得不说蓝心妍很漂亮,我喜欢!
人间胸器
去了美颜滤镜,估计就是大妈了!
期待,不过感觉自己可能用不上了!
天涯不是彻底关闭了吗?
感觉长想一般般!